
Компания проходит несколько стадий на пути к пониманию того, что им нужно зрелое управление данными. Большие данные и аналитика существенно помогают бизнесу. О том, как оптимизировать и монетизировать данные с помощью систем управления, с какими сложностями можно столкнуться, как получить пользу от внедрения, как узнать своего клиента лучше с помощью цифровых технологий, говорили участники секции «BI и большие данные» на CNews FORUM 2019: Информационные технологии завтра.
Качественные данные для бизнеса
Секцию «BI и большие данные» открывал и модерировал Сергей Федечкин, ведущий архитектор по данным ВТБ. Принципиальное отличие его выступления от того, что было год назад, заключалось в том, что в прошлый раз речь шла о теории, а сейчас – о практике внедрения системы управления данными Data Governance в ВТБ. Команде удалось подготовить кейс, который в течении 5 лет выйдет на самоокупаемость.
«На старте возникло 2 вопроса: оптимизировать или монетизировать данные? Мы пошли по консервативному пути и решили сэкономить банку деньги», – рассказал он. Было подготовлено 30 вариантов реализации системы управления данными, в итоге выбрали 3 кейса: карточка юридического лица, единый справочник точек продаж, связка сделка-счет.






В системе управления данными выделили 2 основных блока: бизнес-глоссарий и подсистема управления данными, которая включает в себя систему контроля корректности данных Data Quality. Последняя оказалась самой сложной с точки зрения внедрения. «У нас трепетно относятся к защите данных. Поэтому мы подключались к метаданным, а не загружали данные сами, – пояснил Сергей Федечкин. – Качество данных является одним из самых важных моментов. С одной стороны, мы реализовали технический контроль их корректности, с другой внедрили практику единого окна: заводится инцидент, маршрутизируется в нужную систему и попадает к специалистам, которые отвечают за контроль и корректность».
С глоссарием все было проще. Система была развернута сразу в контуре банка, к ней получили доступ бизнес-пользователи. Ее удалось запустить в эксплуатацию на 1,5 месяца раньше. Главный запрос заказчика заключался в том, чтобы сократить время выхода на рынок. На практике оказалось, что любое изменение бизнес-процессов и внедрение новых элементов ведет к временному снижению скорости вывода продукта. «Внедренные системы мы хотим распространить на DataLake и ожидаем, что помимо экономии для банка, сможем реализовывать бизнес-кейсы, связанные с монетизацией данных, – говорит эксперт. – Мы отказались от пилотного проекта и сразу пошли в полноценный, стартовали в феврале, и уже через 9 месяцев подписали протокол о запуске в промышленную эксплуатацию».
Одно из ключевых условий успеха – это вовлеченность бизнес-пользователей. Сегодня в банке политика релизов определена до конца 2020 г. Есть согласованная с бизнесом стратегия развития систем управления данными и команда для ее реализации.
Проект по внедрению системы управления данными, о которой рассказывал представитель ВТБ, был реализован компанией DIS Group. В своем выступлении на CNews Forum 2019 докладчики DIS Group представили единую систему автоматизации и мониторинга процессов в больших данных. «В этом году мы подписали дистрибьюторский договор с ВМС. Их решения интересны в задачах по большим данным и BI. Хочется отметить, что Data Governance – это в первую очередь помощь в быстром продвижении новых бизнес-идей, – отметил Михаил Комаров, директор направления Informatica DIS Group. – Data Governance позволяет получить нужные данные в нужном месте в нужное время и в нужном качестве».
О решении ВМС Control-M рассказал Евгений Васильев, руководитель направления BMC Software DIS Group. По его словам, в области больших данных сегодня существует зоопарк приложений. В одной и той же компании в разных департаментах задачи могут решаться разными путями. Между приложениями разработчиков, аналитиков и бизнес-сервисами существует непостоянный ландшафт систем, состав которого часто меняется с выходом новых или заменой старых инструментов. Решение ВМС Control-M делает этот ландшафт прозрачным и управляемым, упрощает прогнозирование, поддерживает систему автоматизации, интеграции между приложениями, осуществляет контроль за потоками данных и операциями, отслеживает передачу команд между приложениями.
Продукт изначально развивался как планировщик пакетных заданий. Сегодня он получил вторую жизнь как application integration. Это low-code инструмент, который интегрируется с имеющимися системами SAP, Informatica и вытаскивает оттуда бизнес-процессы и задачи. Его можно ставить сверху над DevOps процессом, контролировать переход приложений, синхронизировать тестовые среды, а также автоматизировать внедрение изменений.
Решение ВМС Control-M обладает множеством преимуществ: сокращение ручного труда, стандартизация процессов, мониторинг в реальном времени, выявление соответствия SLA, уменьшение рисков, связанных с ручными операциями, с уходом ключевых людей и с недокументированными функциями, процессами и скриптами, рассказал Евгений Васильев.
Риски Data Science-проектов
Data Science-проекты и машинное обучение касаются многих сфер. Банки внедряют чат-ботов, оптимизируя нагрузку на колл-центры. Ритейл прогнозирует спрос на товар и сокращает затраты на логистику. Производство оптимизирует обслуживание дорогостоящего оборудования, производственные процессы. Кирилл Дубовиков, технический директор «Синимекс Дата Лаб», выделил ключевые риски Data Science проектов.
Заинтересованный человек предлагает ИТ-команде и аналитикам найти кейс внутри бизнеса. Как правило, такой кейс находят, делают проект, а потом бизнес не понимает, зачем это было нужно. Людям, которые занимаются постановкой задач, часто не хватает знания основ анализа данных. Из-за этого они некорректно ставят задачу или формируют завышенные ожидания, например, предполагая, что искусственный интеллект способен автоматически решить все проблемы.
В Data Science-проектах правильная постановка задачи – это 80% успеха. Она задает метрики, которые затем оптимизируют специалисты по анализу данных. Часто заказчики пытаются использовать традиционные подходы к разработке ПО в проектах по анализу данных. Однако в разработке ПО тестирование начинается с середины проекта или ближе к концу, а в проектах машинного обучения – до первой строчки кода. Случается, что заказчику хочется иметь технологию, а не решить бизнес-задачу. Такой подход имеет право на жизнь, но нужно понимать, что можно реализовать 20 пилотных проектов и не получить никакого результата. «Если мотивация будет идти от бизнеса, и мы будем смотреть на бизнес-процессы, то шансов на успех гораздо больше», – говорит Кирилл Дубовиков.
Как встроить аналитику в бизнес-процессы
«Большие данные и BI – это про людей и для людей, ведь инициатором данных и их пользователем является человек. Когда человек только появился на планете, он уже работал с большими данными, только без компьютера. Он руководствовался приметами, которые передавались от поколения к поколению и помогали адаптироваться к среде, находить себе пищу, выживать в холодный сезон», – начал свое выступление Эдуард Федечкин, ведущий эксперт по системам бизнес-аналитики «Терн».
Он рассказал о внедрении IBM InfoSphere Information Governance Catalog в крупном банке для аудита и ревизии существующих информационных активов. В отделах банка уже существовали отчеты, готовые методологии, решения по оценке того или иного кейса. Проект позволил перенести все это в единое информационное пространство и привести к единой бизнес-терминологии. «28 лет мы занимаемся подобными проектами и используем все лучшие практики и технологии», – говорит Эдуард Федечкин.
Тренды BI технологий
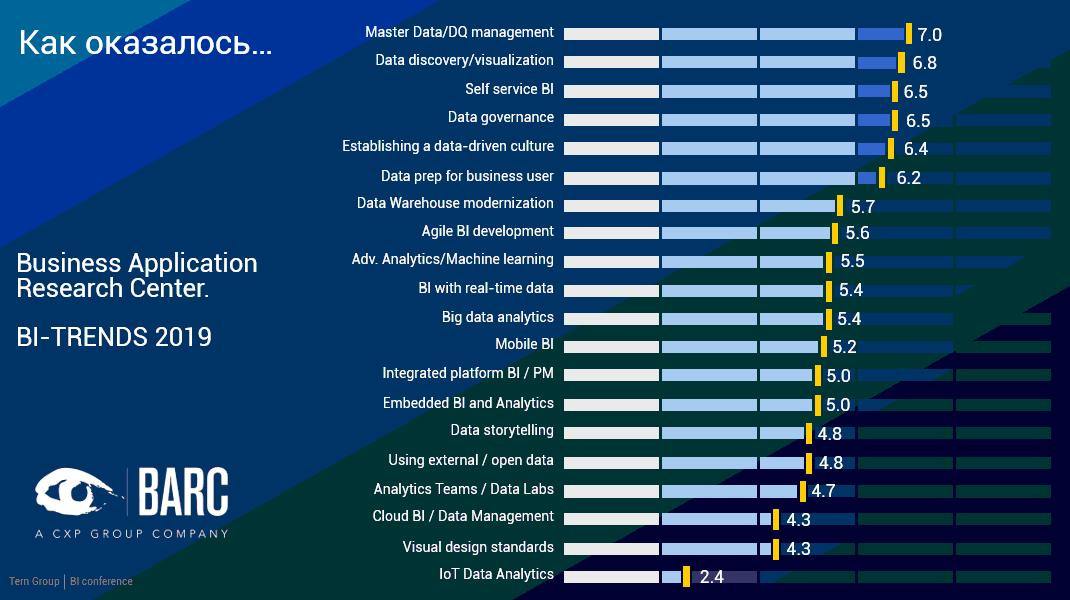
Источник: Терн, 2019
«Насколько эффективны наши рекомендательные системы? Не сажаем ли мы своего клиента в информационную колбу, из которой он уже вряд ли выберется?», – продолжила тему использования BI Мария Артамонова, директор по ИТ «Утконос». По ее мнению, большинство компаний, которые правильно хранят данные и анализируют их, знают своего клиента достаточно хорошо. Правильный нелинейный подход с точки зрения обогащения знаний о клиенте – это попытка предвосхитить ожидания клиента. «И именно так мы стараемся работать. Мы делим клиента по средним чекам и внутри каждой категории анализируем паттерн поведения», – говорит Мария Артамонова.
Она поделилась реальным кейсом. Одна группа покупателей со средним чеком до ₽8 тыс, вторая – от ₽8 тыс. до ₽14 тыс. Отличает их любовь второй группы к бутербродам. По набору продуктов видно, что они покупают нарезку колбасы, сыра, хлеб. При правильно выстроенной коммуникационной компании с первой группой, можно предложить ей набор для бутербродов и таким образом увеличить средний чек.
Кроме того, можно выявлять длинные паттерны с учетом данных других компаний: медицина, туризм, социальные сети. Например, узнать дни рождения друзей клиента, предложить ему варианты подарков. Также важна работа с брошенными корзинами – выявление причин отказа от продукта дает такой же эффект, как история покупок клиента.
«Исторически мы занимались простым бизнесом: производили и продавали сигареты. Одна категория продуктов, клиент хорошо изучен за столетие существования компании: это традиционный потребитель, приверженец конкретной марки», – говорит Дарья Гришина, директор департамента ИТ British American Tobacco. Сегодня рынок табачной индустрии падает, все игроки ищут новые источники прибыли. Не так давно были запущены новые категории продуктов: девайсы, стики.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
С выходом в новые каналы общения с потребителем появилось много новой информации, которую нужно обрабатывать и делать бизнес-выводы. Перед компанией была поставлена задача переместить фокус сотрудников, которые работают над запуском новых аналитических инструментов, с создания традиционных отчетов на предиктивную аналитику. На то, чтобы четко сформулировать, какие системы и источники данных уже есть, а каких не хватает, ушло 1,5 месяца. В результате было сформулировано около 30 вопросов и принято решение об итеративной реализации программы. «Мы приняли решение, что пойдем agile-путем, наши спринты будут не больше пакетов бизнес-задач в 2,5 месяца. Мы интегрировали 4 системы, создали 5 пакетов отчетности и на прошлой неделе получили первую аналитику. Мы уже видим эффективность», – говорит Дарья Гришина.
7 шагов до запуска предиктивной аналитики

Источник: British AmericanTobacco, 2019
Основываясь на практике, она рекомендовала 7 шагов от традиционных разрозненных отчетов в Excel к аналитике больших данных: иметь видение успеха, понимать, что надо получить, инвестировать время в обучение менеджмента компании, выбирать сильного партнера и команду, инвестировать в поддержку качества данных, получать результаты быстро, контролировать, чтобы результат работы использовался на всех уровнях организации.
О возможностях технологий обработки данных рассказал Тамерлан Савлаев, руководитель ДИТ ВДНХ. ВДНХ – это целый город, в котором пилотируется большинство городских технологий. Среди них персонификация и адресная поддержка пользователя на территории, технология навигации людей по парку. В процессе изучения посетителей начался сбор данных о самой территории парка. Было принято решение создать цифровых двойников, которые позволят заниматься предиктивной аналитикой.
На сегодняшний день на ВДНХ бывает около 30 млн человек за год, в ближайшие 3 года оно увеличится на 25%. «Мы хотим также увеличить срок пребывания и средний чек посетителя. Уже зафиксировали задачи: агрегация данных из разных источников, поиск и разработка стратегии управления посетителями, аналитический инструментарий», – говорит Тамерлан Савлаев.
Для создания аналитической системы надо сначала определиться, что должно получиться на выходе, как часто будут происходить обновления, сколько человек будет этим пользоваться. Затем рассчитать бюджет, спланировать срок, все документировать и запустить проект, рассказал Александр Куликов, руководитель отдела BI PepsiCo.
Однако в ходе создания решения могут возникнуть проблемы. Оказывается, что требования, которые были описаны вначале, неполные, неточные или уже изменились. Команда начинает тратить время на доработку, пропускает плановые шаги. Подходит срок завершения проекта. Его продлевают. Думают, что делать дальше. Аутсорсеры уходят и уносят с собой экспертизу, понимание специфики компании и отрасли.
Именно поэтому в PepsiCo решили рассматривать BI не как проект по внедрению, а как программный продукт. «Мы делаем пилот, чтобы убедиться: мы и пользователи думаем одинаково. В следующей итерации начинаем продукт совершенствовать. У пользователей к этому времени формируется конкретный запрос: что еще можно сделать», – пояснил Александр Куликов.
Большие данные в ритейле
У больших данных есть 3 основные характеристики: объем, скорость их прироста в системе и вариативность. Большие данные в ритейле можно поделить на 2 категории: все, что относится к товару, и информация о покупателе. Что же стоит знать, собирать, хранить и анализировать о покупателе в целом? По мнению Алексея Картышева, советника генерального директора по ИТ Ralf Ringer, первое – это основные характеристики: рост, вес и размер. Второе, это способы коммуникации. У каждого покупателя есть телефон, электронная почта, приложение. Важно знать, как и когда с ним коммуницировать, чтобы не быть навязчивым и не отпугнуть предложениями и напоминаниями. «Мы хотим знать покупателя, фиксировать его привычки: как часто он ходит в магазин и меняет вещи. Необходимо понимать, как привлечь покупателя в первый раз и как его удержать. Важно знать, почему покупатель смотрит на конкурентов и отслеживать ценовую политику», – говорит Алексей Картышев.
Как собирать эти данные? Не надо заставлять покупателя заполнять бумажную анкету на кассе, сейчас ее может заменить дисплей, на котором можно быстро нажать кнопки ответов. Самый важный источник информации – это данные чека. Также широко применяется видеоаналитика, с помощью которой можно создавать портрет покупателя, увидеть, что он покупает, и понять, почему.
Информацию нужно правильно хранить, структурировать и работать с ней. Удобно объединять похожие типы покупателей в группы и работать с ними, распространяя инфоповоды каждому представителю в формате личного обращения. На основе данных легко планировать рекламные кампании и акции, заниматься адресными рассылками. Если в магазин заходит постоянный покупатель, и некая технология распознает его на входе, то у кассира или консультанта появляется информация о посетителе, и на ее основе сотрудник сможет четко сформулировать предложения для клиента. Человек поймет, что его здесь знают и готовы предложить то, что он хочет.
«На основе анализа покупательского спроса мы понимаем, какой товар лучше производить, закупать, исключая накопление невостребованных остатков. Привлечение, удержание и возвращение клиентов – в этом круговороте важно понимать причины покупки или отказа от нее. С помощью больших данных можно правильно сформировать витрину»,— поделился Алексей Картышев.
Все для пользователя
В науке растет интерес к тематике Data Management и Data Governance. Внедрять решения для управления данными необходимо с первого дня работы команды, чтобы не потерять ценный цифровой след. Как внедрять? Главное – ориентироваться на пользователя.
Сегодня сотрудник тратит значительную часть времени на поиск информации, большая часть поиска происходит через ввод ключевых слов в поисковых запросах на естественном языке. При этом данные в крупных организациях содержатся в документах объемом более 30 страниц и они не структурированы.
Количественные оценки трендов в управлении данными

Источник: ВШЭ, 2019
По словам Ильи Кузьминова, директора центра стратегической аналитики и больших данных ИСИЭЗ НИУ ВШЭ, когда мы имеем острова данных, которые появляются в разных отделах организации, а отдельные хранилища данных изолированы своими онтологиями со своими нотациями и плохо связываются между собой, то понимаем: чтобы все это интегрировать и использовать, нужен семантический анализ текста.
Раньше управление данными и управление знаниями являлись разными вещами. С появлением нового инструментария, платформенных решений, возможности строить действительно бесшовную, прозрачную и незаметную для пользователя ИТ-экосистему в компании, эти понятия начинают сливаться. При этом задача ИТ-департамента заключается в том, чтобы создавать удобные в использовании инструменты. Иначе они не будет востребованы.
Например, если в корпоративной системе язык запроса достаточно сложный, система долго запускается, нужно заходить на несколько порталов, то когда у пользователя возникает вопрос, ему проще обратиться к гуглу. А значит, созданная в организации система выстроена неправильно. «Идеология следующая: ни в коем случае не заставлять пользователя работать в сложном интерфейсе, что-то заполнять. Мы должны максимально облегчить его работу», – говорит Илья Кузьминов.
В июле 2018 г. был подписан 209-ФЗ о том, что во всех публичных акционерных обществах должен быть внедрен риск-менеджмент. Внедрение цифровой системы управления инвестиционными проектами и рисками стало необходимым. О том, как это происходит, рассказала Яна Крухмалева, руководитель проекта внедрения цифровой системы управления инвестиционными проектами и рисками «Газпром».
По ее словам, при реализации крупных международных инвестиционных проектов, основанных на принципах проектного финансирования, риски надо разделить еще на этапе заключения акционерного соглашения. Согласно международной статистике. большинство проектов реализуется не в срок и выходит за рамки бюджета.
Особенности реализуемых комплексных проектов

Источник: Газпром, 2019
Исполнители проектов стремятся занизить показатели, чтобы привлечь инвестора. Причина, на которую часто списывается превышение затрат, – это форс-мажоры. Все знают, что риски есть, но не знают, как ими управлять. Яна Крухмалева рассказала о негативном опыте проекта «Южный поток». В 2009 г. был подписан пакет, направленный на либерализацию энергетического рынка. Суть его в том, что одно юридическое лицо не может одновременно быть оператором газопровода и продавать газ. Европейцы видели в этом монополизацию. Подрядчик не обратил внимание на эту угрозу. Европейцы начали саботировать проект, в результате в 2014 г. он был переориентирован на Турцию.
Сегодня «Газпром» внедряет отечественное решение по анализу рисков от разработчика, который существует на рынке больше 5 лет. Появились новые технологии, позволяющие предвосхитить множество рисков. Например, технология, которая позволяет по звуковой волне определить благонадежность сотрудника, или семантический анализ переписки, который предсказывает, что сотрудник собрался увольняться.
Самое широкое применение находит роботизация. Так, сегодня в «Газпроме» используется алгоритм, помогающий отслеживать хищение газа. Над объектами летают дроны, которые в режиме реального времени демонстрируют, как продвигается строительство объекта. И это лишь несколько примеров. «Кто владеет информацией, тот владеет миром», –говорит Яна Крухмалева.

О развитии технологий искусственного интеллекта для обработки больших данных рассказал Кирилл Дубовиков, технический директор «Синимекс Дата Лаб».
CNews: Что обычно понимается под технологией Data Science/Big Data? Что это на практике?
Кирилл Дубовиков: Data Science и Big Data представляют из себя две разные дисциплины. Data Science решает бизнес-задачи с помощью сбора, обработки и анализа данных. Big Data – это больше про инженерию, когда есть потребность в обработке большого объема данных, подсчете или соединении нескольких их источников.
Презентации участников