На российский рынок аналитики больших данных выходят новые поставщики, а традиционные вендоры продолжают выпускать новые продукты. Это происходит, несмотря на общее неустойчивое положение рынка и значительное снижение порога входа в топ-10 рейтинга CNews «Крупнейшие поставщики BI-решений в России». Актуальные вопросы развития технологий больших данных обсудили участники конференции CNews «Большие данные 2016»
Объемы корпоративной информации постоянно увеличиваются и составят, по данным Gartner, 44 зеттабайт данных (44 трлн гигабайт) к 2020 г. Соответственно, растет и быстро формирующийся рынок технологий больших данных. По прогнозам Wikibon, к тому же 2020 г. его объем вырастет до $60 млрд, при том, что аналитики отмечают снижение темпов роста с 40% до 26%. Активный рост рынка не только способствует развитию технологий, но и привлекает на него игроков, заработавших ранее репутацию в других отраслях.
Китайский гигант Huawei, известный в нашей стране как один из крупнейших мировых поставщиков решений для телекома, подтвердил свое решение активно бороться за другие рынки и показать себя как вендора решений для ИТ в целом. Об этом на мероприятии, организованном отделами конференций и аналитики CNews говорил менеджер по техническим решениям Huawei Пётр Предтеченский. «Только в центрах RnD работают 79 тыс. сотрудников, из них 120 имеют специализацию Data Scientist, причем часть работает в России. Инвестиции Huawei в RnD только за 2015 год составили $7,7 млрд», – сообщил эксперт. В России компания уже имеет завершенный проект создания облачного решения и ведет пилотные проекты с операторами.
По словам Петра Предтеченского, наиболее перспективными технологиями и продуктами для больших данных сегодня являются Hadoop и Spark, в которые компания активно инвестирует ресурсы. Что касается отраслей, то локомотивами Big Data по-прежнему остаются телекоммуникационные компании и банки.
Структура платформы для обработки больших данных
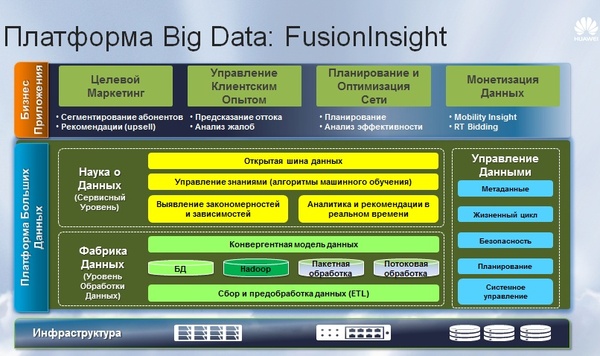
Источник: Huawei, 2016
Его коллега из компании Qlik, архитектор решений Сергей Полехин призвал аудиторию не гнаться за крупными инфраструктурными проектами – они понадобятся для тиражирования решений на большое число пользователей. Значительное число проектов, связанных с большими данными, по его словам, нужны только определенному кругу людей, которые знают, что будут делать с этими данными. Такие аналитические задачи можно решать при помощи легких готовых инструментов.
На рынке аналитики больших данных усиливают свое присутствие и российские компании. Так, директор по продажам PROMT Никита Шаблыков впервые на конференции CNews представил новый PROMT Analyser – систему для поиска, извлечения и обобщения информации из неструктурированных текстовых данных на разных языках. Использование лингвистических технологий для анализа неструктурированных текстовых данных существенно сокращает временные затраты на аналитику и повышает точность анализа. Она позволяет, в частности, не только работать с данными по ключевым словам, но и анализировать текст для того чтобы отнести те или иные слова к ключевым. Например, если в тексте говорится о конкретном человеке, то система выделит фразы как с именем, так и с другими словами, относящимися к нему.
PROMT Analyser

Источник: PROMT, 2016
Как использовать большие данные: варианты
Существуют два подхода к анализу больших данных: классический BI и Advanced Analytics. Первый отвечает на простые вопросы: «Когда? Кто? Как? Сколько?» и т. п., а второй подход позволяет оценивать, почему происходят те или иные события, что будет при выполнении определенных условий и произойдет ли событие снова. «Неотъемлемой и важной частью Advanced Analytics является текстовая аналитика. Она позволяет добывать данные в реальном времени из различных источников, категоризировать их, извлекать значимую информацию с выделением заданных сущностей и отправкой данных в CRM, анализировать мнения по их тональности и другим признакам, а также самообучаться», – говорит Илья Вигер, СЕО компании Vesolv. В частности, возможности текстовой аналитики позволили Vesolv создать такое интересное решение, как модуль «Голос клиента» для автоматической агрегации и анализа клиентского опыта.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Александр Скакунов, генеральный директор «ВолгаБлоб» напомнил, что основная проблема больших данных никуда не делась – их объемы растут экспоненциально, что вызывает беспокойство у поставщиков решений и их клиентов. Докладчик рассказал, что его компания собрала существующие решения и классифицировала их по решаемым задачам – от Service Desk до бизнес-аналитики. Об основных вариантах он рассказал участникам конференции. По его словам, «если взять среднюю или крупную компанию, то ее источники генерируют данные, которые могут быть использованы во всех сферах применения, то есть компания использует один и тот же массив данных». Этот подход позволил компании разработать решение, которое формирует единое хранилище данных из всех источников – от логов информационных систем до данных мобильных приложений, и распределять эти данные по отделам компании. Такой способ, когда пользователям доступны вообще все данные и их комбинации, позволяет проводить анализ в необычных разрезах и получать недоступные раньше результаты.
Пётр Предтеченский: Руководство должно быть готово принимать бизнес-решения на основе данных

Пётр Предтеченский, менеджер по техническим решениям, Huawei, перечислил пять правил для успешного использования технологий в области больших данных.
CNews: Какие направления в разработке решений, которые можно отнести к сегменту технологий больших данных, вы считаете наиболее перспективными и почему?
Пётр Предтеченский: Здесь можно выделить технологический и бизнес-аспекты. Технологический аспект – это сдвиг от классической парадигмы Map/Reduce к масштабируемым вычислениям в памяти. Наиболее известный пример – Apache Spark. Стоимость памяти неуклонно снижается, серверы с оперативной памятью, измеряемой терабайтами, становятся нормой. Скорость обработки вырастает на порядки, при этом сохраняется возможность обрабатывать огромные массивы данных.